
Úvod: Neúprosná Dynamika Digitálneho Sveta a Vznik Nových Výziev
V raných fázach vývoja internetu, a metaforicky povedané, od „narodenia“ prvých digitálnych infraštruktúr, sa interakcia medzi používateľmi a webovými službami predpokladala predovšetkým ako priama a zámerná. S rastúcou komplexnosťou a všadeprítomnosťou internetu sa však objavili nové, nepredvídané výzvy. Svet digitálnych dát sa stal obrovským zdrojom informácií, ktorý láka nielen legitímnych používateľov, ale aj automatizované systémy a nástroje známe ako „web scraperi“ alebo „boty“. Tieto nástroje, hoci niektoré slúžia na legitímne účely, ako je indexovanie vyhľadávačmi alebo monitorovanie cien, sa často zneužívajú na nežiaduce masové získavanie dát, ktoré môže mať vážne dôsledky pre prevádzkovateľov webových stránok.
Problém masového web scrapingu a automatizovaných interakcií sa rozvinul do komplexnej digitálnej šachovej partie, kde sa neustále vyvíjajú nové metódy obchádzania ochrany, ako aj nové protiopatrenia. Táto dynamika núti vývojárov a bezpečnostných expertov neustále inovovať svoje prístupy k identifikácii a riadeniu internetového prevádzky. Cieľom je zabezpečiť plynulý chod služieb pre skutočných ľudí a zároveň efektívne blokovať škodlivé aktivity botov. V tomto kontexte sa prehodnocujú tradičné bezpečnostné modely a hľadajú sa sofistikovanejšie metódy na odlíšenie digitálnej identity legitímneho používateľa od automatizovaného agenta.
1. Eskalácia Nákladov Pri Masívnom Web Scrapingu: Od Zanedbateľného Zaťaženia k Systémovej Hrozbe
Web scraping, teda automatizované sťahovanie obsahu z webových stránok, predstavuje dvojsečnú zbraň digitálneho veku. Na jednej strane môže byť prospešný pre výskum trhu, agregáciu dát alebo SEO analýzu. Na strane druhej, ak sa vykonáva masívne a bezohľadne, môže prerásť do významnej finančnej a prevádzkovej záťaže pre prevádzkovateľov webových služieb. Na individuálnej úrovni je dodatočné zaťaženie generované jedným scraperom alebo niekoľkými požiadavkami často zanedbateľné a ľahko absorbovateľné bežnou webovou infraštruktúrou. Väčšina moderných serverov a cloudových riešení je navrhnutá tak, aby zvládla fluktuácie v dopyte a nárazové zaťaženie. Ak jeden bot vykoná niekoľko desiatok alebo dokonca stoviek požiadaviek za deň, celkový vplyv na výkon, šírku pásma alebo databázové operácie zostáva minimálny. Takáto úroveň aktivity sa často považuje za súčasť bežného webového prevádzky, hoci si môže vyžadovať základné monitorovanie.
Situácia sa dramaticky mení, keď sa aktivita scraperov kumuluje. Pri úrovni masového scrapingu sa kumuluje zaťaženie z tisícov, desaťtisícov alebo dokonca státisícov automatizovaných požiadaviek a výrazne zvyšuje náklady na scraping pre prevádzkovateľov webových stránok. Tento hromadný efekt je podobný efektu snežnej gule, kde malá počiatočná sila naberie obrovské rozmery. Webové servery sú nútené spracovávať neúmerné množstvo požiadaviek, čo vedie k zvýšenej spotrebe procesorového času, pamäte a diskových operácií. Dôsledkom je zníženie výkonu pre legitímnych používateľov, spomalenie načítania stránok, a v extrémnych prípadoch dokonca úplné výpadky služby (Denial of Service - DoS). Pre prevádzkovateľov to znamená nielen stratu potenciálnych zákazníkov v dôsledku frustrujúceho používateľského zážitku, ale aj priame finančné náklady. Musia investovať do drahších serverových balíkov, rozsiahlejšej šírky pásma, sofistikovanejších systémov na vyrovnávanie záťaže a pokročilých riešení na detekciu a blokovanie botov.
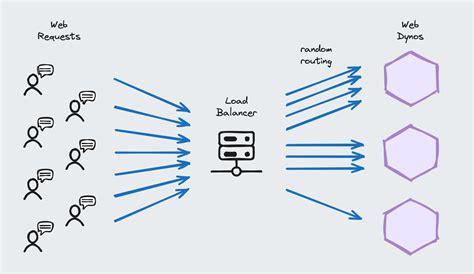
Okrem priamych prevádzkových nákladov existujú aj nepriame ekonomické dôsledky. Masové získavanie dát môže viesť k úniku citlivých informácií, poškodeniu duševného vlastníctva, strate konkurečnej výhody (napríklad pri scrapingu cien), a k narušeniu integrity dát. Napríklad, ak scraperi neustále extrahujú a publikujú obsah, ktorý je chránený autorskými právami, môže to viesť k právnym sporom a poškodeniu reputácie. V odvetviach, kde sú dáta kľúčovou komoditou, ako je e-commerce, cestovný ruch alebo finančníctvo, môže masový scraping ohroziť celý obchodný model. Preto sa boj proti masívnemu scrapingu stáva nielen technickou, ale aj strategickou a ekonomickou prioritou pre každú organizáciu pôsobiacu online.
2. Od Dočasných Riešení k Sofistikovanej Identifikácii: Prechod od Zástupných Opatrení
Vývoj webových technológií a zručnosť útočníkov si vyžaduje neustálu adaptáciu obranných mechanizmov. Počiatočné pokusy o obranu proti botom sa často spoliehali na jednoduché a ľahko implementovateľné riešenia, ktoré však z dlhodobého hľadiska neboli udržateľné. Tieto zástupné riešenia, ako sú jednoduché systémy CAPTCHA vyžadujúce rozpoznávanie deformovaného textu alebo základné obmedzenia rýchlosti požiadaviek (rate limiting), boli často prvou líniou obrany. Hoci na určitý čas dokázali odradiť menej sofistikovaných botov, ich účinnosť bola obmedzená. Moderné automatizované systémy a nástroje umelej inteligencie sú schopné s vysokou presnosťou riešiť aj zložité CAPTCHA úlohy, a obmedzenia rýchlosti sa dajú ľahko obísť distribúciou útokov cez rozsiahle siete botnetov alebo cez proxy servery.
Takéto zástupné riešenia navyše často narúšajú používateľský zážitok. Neustále predkladanie CAPTCHA úloh alebo blokovanie používateľov pri prekročení určitých limitov môže frustrovať legitímnych návštevníkov, viesť k ich odchodu z webu a zníženiu konverzií. Prevádzkovatelia webových stránok si uvedomujú, že prioritou je zabezpečiť plynulý a bezproblémový prístup pre skutočných používateľov. Preto je snaha o minimalizáciu rušivých prvkov kľúčová. V konečnom dôsledku ide o zástupné riešenie, aby sa viac času mohlo venovať odtlačkom prstov (fingerprinting) a identifikácii bezhlavých prehliadačov (headless browsers) (Napríklad: podľa toho, ako vykresľujú písma), aby sa stránka s výzvou na preukázanie práce nemusela prezentovať používateľom, ktorí sú omnoho pravdepodobnejšie legitímnymi.
Tento posun v stratégii odráža hlbšie pochopenie problematiky. Namiesto všeobecného blokovania prevádzky alebo kladenia prekážok pre všetkých, sa pozornosť presúva na cielenú identifikáciu skutočnej povahy prístupujúceho agenta. Pokročilé techniky, ako je vytváranie digitálnych odtlačkov prstov prehliadačov a detekcia bezhlavých prehliadačov, umožňujú detailnejšiu analýzu a diferencovaný prístup. Namiesto paušálnych blokácií alebo otravných overovaní sa tak môžu webové služby dynamicky rozhodovať, či daný používateľ pravdepodobne predstavuje bota alebo legitímnu osobu. Tento prístup nielenže zlepšuje obranu proti sofistikovaným útokom, ale zároveň výrazne zlepšuje používateľský zážitok pre skutočných návštevníkov tým, že ich šetrí od zbytočných a časovo náročných overovacích krokov. Je to investícia do inteligencie a presnosti namiesto hrubej sily a plošných obmedzení.
3. Digitálne Odtlačky Prstov (Fingerprinting): Nová Hranica v Detekcii Botov
Digitálne odtlačky prstov, známe aj ako browser fingerprinting, predstavujú jednu z najpokročilejších a najsofistikovanejších techník na identifikáciu unikátnych návštevníkov webových stránok, vrátane botov. Na rozdiel od jednoduchého sledovania pomocou súborov cookie, ktoré môžu byť ľahko vymazané alebo zablokované, odtlačky prstov sa spoliehajú na zber a analýzu rozsiahlej sady konfiguračných a technických parametrov, ktoré dohromady tvoria jedinečný "digitálny podpis" každého prehliadača alebo zariadenia. Myšlienka spočíva v tom, že aj keď dva prehliadače navonok vyzerajú rovnako, malé rozdiely v ich nastaveniach, hardvéri alebo softvéri môžu vytvoriť unikátny profil.
Medzi kľúčové dátové body, ktoré sa používajú na vytváranie odtlačkov prstov, patria:
- User-Agent reťazec: Poskytuje informácie o prehliadači, operačnom systéme a verzii.
- Rozlíšenie obrazovky a hĺbka farieb: Špecifické nastavenia monitora používateľa.
- Zoznam nainštalovaných písiem: Scraperi často nemajú nainštalované všetky bežné písma, čo môže byť indikátorom.
- Podpora a verzia pluginov a rozšírení: Aj keď je používanie tradičných pluginov (ako Flash) na ústupe, informácie o rozšíreniach prehliadača môžu byť cenné.
- Nastavenia jazyka a časového pásma: Lokálne nastavenia systému.
- Parametre WebGL a Canvas: Unikátne vykresľovanie grafiky pomocou WebGL (Web Graphics Library) alebo kreslenie na plátne (Canvas) môže odhaliť hardvérové a softvérové rozdiely, dokonca aj medzi identickými modelmi GPU. Napríklad, malé variácie v implementácii grafických ovládačov môžu viesť k mikroskopickým rozdielom vo vykreslených obrazoch, ktoré sú pre ľudské oko neviditeľné, ale pre algoritmy detekcie zásadné.
- Informácie o audio kontexte: Analýza zvukového hardvéru a jeho schopností.
- Výkonnosť systému a siete: Meranie oneskorenia a rýchlosti spracovania JavaScriptu.
- Charakteristika TCP/IP staku: Rozdiely v spôsobe, akým operačné systémy implementujú TCP/IP protokoly.
Jedným z príkladov uvedených v kontexte detekcie bezhlavých prehliadačov je, ako vykresľujú písma. Aj keď sa to zdá byť detailom, spôsob, akým prehliadač vykresľuje text (antialiasing, hinting, rozostupy medzi znakmi), je závislý od operačného systému, verzie prehliadača, nainštalovaných písiem a dokonca aj od hardvérových ovládačov. Bezhlavé prehliadače, ktoré bežia často vo virtuálnych prostrediach alebo na serveroch bez plnej grafickej akcelerácie, môžu vykazovať odlišné vykresľovanie písiem v porovnaní so štandardným desktopovým prehliadačom. Tieto subtilné rozdiely je možné zachytiť prostredníctvom JavaScriptu a porovnať ich s očakávaným štandardom. Ak sa zistí výrazná anomália, môže to byť silný indikátor prítomnosti bota.
Jedinečnosť a perzistencia odtlačkov prstov robí z tejto techniky silný nástroj proti botom. Aj keď sa bot snaží meniť IP adresy, súbory cookie alebo user-agent reťazce, zmena všetkých parametrov, ktoré tvoria odtlačok prsta, je oveľa ťažšia. To umožňuje prevádzkovateľom webových stránok spájať rôzne "návštevy" s rovnakým základným agentom, aj keď sa pokúša maskovať. Samozrejme, s rastúcou efektivitou fingerprintingu rastú aj obavy o súkromie používateľov. Schopnosť neustále sledovať používateľov bez ich explicitného súhlasu predstavuje etickú dilemu a vedie k vývoju protiopatrení na strane prehliadačov a bezpečnostných pluginov, ktoré sa snažia tieto techniky zmazať alebo obmedziť.
4. Bezhlavé Prehliadače (Headless Browsers) a Ich Maskovanie
Bezhlavé prehliadače (headless browsers) predstavujú významný evolučný krok v oblasti webovej automatizácie a zároveň predstavujú jednu z najväčších výziev pre systémy detekcie botov. Názov "bezhlavý" odkazuje na skutočnosť, že tieto prehliadače nemajú grafické používateľské rozhranie (GUI). Fungujú na pozadí, podobne ako bežný prehliadač, ale bez zobrazenia okna, kariet, panelov nástrojov alebo iných vizuálnych prvkov. Sú to v podstate programovateľné API, ktoré umožňujú interagovať s webovými stránkami programovo.
Ich primárne legitímne použitie je v oblasti automatizovaného testovania webových aplikácií, generovania PDF súborov z webových stránok, vykonávania úloh na serveri, alebo pri monitorovaní zmien obsahu. Nástroje ako Puppeteer (pre Chrome/Chromium) a Selenium (podporujúce rôzne prehliadače, vrátane ich bezhlavých režimov) sú populárne vo vývojárskych komunitách pre svoju flexibilitu a robustnosť. Umožňujú vývojárom simulovať interakcie skutočného používateľa, ako je klikanie na odkazy, vypĺňanie formulárov, navigácia a dokonca aj spúšťanie JavaScriptu na stránke, a to všetko bez vizuálnej réžie.
Problém pre webovú bezpečnosť nastáva, keď sú bezhlavé prehliadače zneužívané na masívny web scraping a iné škodlivé aktivity. Pretože dokážu plne interpretovať JavaScript, CSS a simulovať realistické interakcie s webovými stránkami, sú oveľa ťažšie detekovateľné ako tradičné jednoduché skripty, ktoré len stiahnu HTML obsah. Scraperi ich používajú na to, aby sa vydávali za legitímnych používateľov, obchádzali základné ochranné mechanizmy a systematicky extrahovali dáta vo veľkom rozsahu. Tým sa snažia imitovať správanie človeka, aby sa vyhli detekcii.

Techniky na detekciu bezhlavých prehliadačov sa neustále vyvíjajú a sú čoraz sofistikovanejšie. Spoliehajú sa na jemné, ale konzistentné rozdiely medzi bezhlavým a tradičným prehliadačom:
- Špecifické JavaScriptové vlastnosti: Bezhlavé prehliadače často zanechávajú stopy vo svojom JavaScriptovom prostredí. Napríklad, niektoré globálne objekty alebo vlastnosti (ako
window.navigator.webdriveralebo špecifické interné premenné) môžu byť prítomné alebo mať odlišné hodnoty v bezhlavom režime, ktoré v bežnom prehliadači chýbajú alebo sú iné. - Chýbajúce prvky používateľského rozhrania: Hoci bezhlavý prehliadač neukazuje GUI, niekedy môže prezradiť svoju povahu tým, že sa pokúsi získať prístup k API, ktoré by v skutočnosti neexistovalo bez vizuálnych prvkov (napr. informácie o lištách posúvania alebo zobrazenie upozornení).
- Subtílne rozdiely vo vykresľovaní: Ako už bolo spomenuté, vykresľovanie obsahu, najmä písiem, WebGL a Canvas grafiky, môže byť odlišné v bezhlavých prostrediach. Nedostatok hardvérovej akcelerácie alebo špecifických knižníc môže viesť k detekovateľným variáciám. Tieto rozdiely sú pre ľudské oko nepostrehnuteľné, ale sofistikované algoritmy ich dokážu identifikovať.
- Behové prostredie: Bezhlavé prehliadače sú často spustené v kontajneroch (napr. Docker) alebo na serveroch, ktoré majú odlišné charakteristiky operačného systému a siete v porovnaní s bežnými desktopovými alebo mobilnými zariadeniami. Monitorovanie týchto environmentálnych stôp môže pomôcť pri ich identifikácii.
- Analýza správania: Hoci bezhlavé prehliadače môžu imitovať ľudské správanie, často zlyhávajú v jemných detailoch. Napríklad, môžu mať príliš konzistentné časovanie interakcií, neštandardné pohyby myši, alebo príliš rýchlo spracúvajú formuláre. Detekcia takýchto anomálií si vyžaduje rozsiahlu analýzu dát a často aj strojové učenie.
Boj proti bezhlavým prehliadačom je neustálym závodom v zbrojení, kde sa obrancovia snažia nájsť nové detekčné metódy a útočníci sa snažia svoje boty ešte lepšie maskovať.
5. Úloha JavaScriptu v Moderných Antirobotických Systémoch a Konflikty s Bezpečnostnými Pluginmi
JavaScript sa stal pilierom moderných webových aplikácií a rovnako dôležitým nástrojom v arzenáli proti botom. Jeho schopnosť vykonávať komplexné operácie priamo na strane klienta (v prehliadači používateľa) ho robí neoceniteľným pre sofistikované systémy detekcie a prevencie botov. Tradičné metódy, ktoré sa spoliehali len na serverovú analýzu IP adries alebo jednoduché hlavičky HTTP, sú už dávno prekonané. Moderné antirobotické riešenia využívajú JavaScript na zber bohatého súboru informácií o prehliadači a správaní používateľa, čo umožňuje oveľa presnejšiu identifikáciu.
Medzi kľúčové aplikácie JavaScriptu v boji proti botom patria:
- Zber dát pre fingerprinting: JavaScript je primárny nástroj na získavanie všetkých tých detailov, ktoré tvoria digitálny odtlačok prsta prehliadača - od zoznamu nainštalovaných písiem, cez parametre WebGL a Canvas, až po špecifické vlastnosti DOM (Document Object Model) a prehliadačového API. Dokáže testovať rôzne aspekty prostredia prehliadača, ktoré by sa bez neho nedali zistiť.
- Analýza správania klienta: JavaScript môže monitorovať interakcie používateľa na stránke v reálnom čase. Sleduje pohyby myši, stláčanie kláves, čas strávený na jednotlivých elementoch, rýchlosť navigácie a iné vzory správania. Ľudské správanie je často nepravidelné a plné mikro-anomálií, zatiaľ čo boty majú tendenciu k opakovaným, precíznym a často nadpriemerne rýchlym akciám. Tieto rozdiely môže JavaScript zachytiť a odoslať na analýzu.
- Dynamické výzvy a overovanie: Namiesto statických CAPTCHA úloh môže JavaScript implementovať adaptívne výzvy. Napríklad, môže dynamicky generovať a vkladať "neviditeľné" polia do formulárov, ktoré by mali zostať prázdne pre legitímneho používateľa, ale bot by ich mohol vyplniť. Alebo môže inicializovať malé výpočtové úlohy na strane klienta (proof-of-work), ktoré zaťažujú botov bez toho, aby si ich legitímny používateľ všimol.
- Šifrovanie a obfuskácia kódu: Kód JavaScriptu pre detekciu botov je často obfuskovaný (zámerne sťažený na čítanie), aby sa zabránilo spätnému inžinierstvu a obchádzaniu útočníkmi.
Systémy ako "Anubis" (použitý ako príklad v pôvodnom texte) sú príkladmi komplexných antirobotických riešení, ktoré sa spoliehajú na rozsiahle využitie moderných funkcií JavaScriptu. Tieto funkcie zahŕňajú napríklad Promises, Fetch API, Web Workers, ES6+ syntax a iné pokročilé možnosti, ktoré umožňujú efektívnejšie a robustnejšie vykonávanie detekčných algoritmov. Avšak táto závislosť na pokročilých JavaScriptových funkciách vytvára inherentný konflikt s určitými bezpečnostnými a súkromie chrániacimi pluginmi prehliadačov.
Je potrebné poznamenať, že Anubis vyžaduje použitie moderných funkcií JavaScriptu, ktoré pluginy ako JShelter deaktivujú. JShelter je rozšírenie prehliadača zamerané na ochranu súkromia, ktoré maskuje alebo blokuje určité JavaScriptové API a funkcie, aby zabránilo webovým stránkam v zbere rozsiahlych dát o používateľovi a vytváraní jeho odtlačkov prstov. Blokovaním týchto funkcií JShelter účinne chráni súkromie používateľov pred sledovaním. Ironicky, tým však zároveň narúša funkcionalitu antirobotických systémov, ktoré sa na tieto isté funkcie spoliehajú pri odhaľovaní škodlivých botov. Pre legitímneho používateľa, ktorý si cení svoje súkromie a používa takéto pluginy, to môže znamenať, že bude omylom identifikovaný ako bot alebo bude nútený podstupovať dodatočné overovacie kroky. Tento konflikt poukazuje na neustále napätie medzi online bezpečnosťou, ochranou súkromia a plynulým používateľským zážitkom. Weboví prevádzkovatelia a vývojári musia neustále hľadať rovnováhu a vytvárať riešenia, ktoré sú účinné proti botom, no zároveň rešpektujú súkromie a neobťažujú legitímnych používateľov.
6. Výzvy Na Preukázanie Práce (Proof-of-Work Challenges): Kompromis Medzi Bezpečnosťou a Používateľským Zážitkom
Výzvy na preukázanie práce, často označované ako Proof-of-Work (PoW) challenges, predstavujú kľúčový obranný mechanizmus v boji proti automatizovaným útokom a masívnemu scrapingu. Ich základná myšlienka spočíva v tom, že vyžadujú od prístupujúceho klienta vykonanie určitého množstva výpočtovej práce predtým, než mu bude udelený prístup k požadovaným zdrojom. Pre legitímneho používateľa je táto práca často zanedbateľná a zväčša nebadateľná, zatiaľ čo pre bota, ktorý sa snaží vykonávať tisíce požiadaviek za sekundu, sa náklady na vykonanie tejto práce kumulujú a stávajú sa finančne neudržateľnými alebo časovo náročnými.
Najznámejším príkladom PoW výzvy v kontexte webu sú systémy CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart). Ich cieľom je odlíšiť človeka od stroja zadaním úlohy, ktorú človek dokáže ľahko vyriešiť, ale pre počítač je obtiažna. Pôvodné CAPTCHA vyžadovali rozpoznávanie deformovaného textu, no s rozvojom umelej inteligencie a strojového učenia sa tieto systémy stali menej efektívnymi. V reakcii na to sa objavili sofistikovanejšie vizuálne CAPTCHA, ktoré vyžadujú napríklad identifikáciu objektov na obrázkoch, alebo tzv. "invisible CAPTCHA", ktoré analyzujú správanie používateľa (pohyby myši, rýchlosť vypĺňania formulárov) na pozadí a len v prípade podozrenia predložia vizuálnu výzvu.
Okrem vizuálnych CAPTCHA existujú aj čisto výpočtové PoW výzvy. Tieto systémy vyžadujú, aby prehliadač klienta vyriešil malý kryptografický problém alebo vykonal krátky, ale výpočtovo náročný algoritmus na strane klienta prostredníctvom JavaScriptu. Čas potrebný na vyriešenie takejto úlohy je pre jeden legitímny dopyt zanedbateľný (napríklad pár milisekúnd), no pre bota, ktorý generuje tisíce požiadaviek, sa táto kumulovaná výpočtová réžia stáva prohibitívnou. Bot by musel buď vynaložiť obrovské množstvo výpočtových zdrojov, alebo by bol výrazne spomalený, čo narúša jeho schopnosť efektívne vykonávať masový scraping.
Hlavným cieľom týchto systémov je, aby sa stránka s výzvou na preukázanie práce nemusela prezentovať používateľom, ktorí sú omnoho pravdepodobnejšie legitímnymi. To znamená, že sofistikované antirobotické systémy sa snažia kombinovať rôzne metódy (ako fingerprinting, analýza správania a detekcia bezhlavých prehliadačov) s cieľom najprv určiť pravdepodobnosť, či je používateľ človekom alebo botom. Ak je pravdepodobnosť, že ide o legitímneho používateľa, vysoká, PoW výzva sa mu vôbec nepredkladá, čím sa minimalizuje trenie a zlepšuje používateľský zážitok. Výzvy sú vyhradené len pre tých, ktorí sú vysoko podozriví, alebo pre tých, o ktorých systémy nemajú dostatok informácií na jednoznačnú identifikáciu.
Napriek ich účinnosti existuje neustály kompromis medzi bezpečnosťou a používateľským zážitkom. Príliš agresívne alebo časté PoW výzvy môžu frustrovať legitímnych používateľov a viesť k ich odchodu. Preto je kľúčové nastaviť tieto mechanizmy tak, aby boli dostatočne robustné na odrazenie botov, ale zároveň čo najmenej invazívne pre skutočných ľudí. Neustále sa hľadajú inovácie v oblasti "neviditeľných" výziev, ktoré fungujú na pozadí bez nutnosti priamej interakcie používateľa, čím sa dosahuje rovnováha medzi zabezpečením a plynulým online prostredím.
7. Komplexnosť Správy Botov a Budúcnosť Webovej Ochrany
Správa botov (bot management) a ochrana webových aplikácií pred automatizovanými hrozbami je nepretržitým a mimoriadne komplexným procesom, ktorý sa nedá vyriešiť jednorazovým riešením. Je to dynamický a adaptívny "závod v zbrojení" medzi obrancami a útočníkmi, kde sa neustále vyvíjajú nové stratégie a technológie na oboch stranách. Prevádzkovatelia webových stránok a bezpečnostní experti musia neustále inovovať a implementovať viacvrstvové obranné stratégie, aby udržali krok s rastúcou sofistikovanosťou útokov.
Kľúčom k efektívnej ochrane je multi-vrstvový prístup, ktorý kombinuje rôzne techniky a analyzuje dáta z viacerých zdrojov. To zahŕňa tradičné metódy ako firewall, obmedzenie rýchlosti (rate limiting) a blacklisty IP adries, no tieto sú doplnené o oveľa pokročilejšie mechanizmy. Medzi ne patria rozsiahle fingerprinting prehliadačov (ako už bolo podrobne opísané), hĺbková analýza správania používateľa v reálnom čase, detekcia anomálií a špecifických stôp zanechaných bezhlavými prehliadačmi, a implementácia adaptívnych výziev na preukázanie práce. Celý tento komplexný systém funguje ako orchestra, kde každý nástroj prispieva k celkovému obrazu o prichádzajúcom prevádzke.
Budúcnosť webovej ochrany pred botmi je úzko spojená s pokrokom v oblasti umelej inteligencie (AI) a strojového učenia (ML). Algoritmy ML sú schopné spracovávať obrovské objemy dát v reálnom čase, identifikovať komplexné vzory a korelácie, ktoré sú pre človeka príliš zložité na rozpoznanie. To im umožňuje detegovať aj veľmi subtílne odchýlky od normálneho ľudského správania alebo charakteristik prehliadačov, ktoré by inak zostali neodhalené. Súčasné systémy dokážu dynamicky prispôsobovať svoje modely detekcie novým typom útokov, čím sa stávajú odolnejšími voči evolúcii botov. Behaviorálna biometria, ktorá analyzuje jedinečné vzorce interakcie človeka (napr. stlačenie kláves, pohyb myši, dotyk), sa stáva ďalšou hranicou v presnejšej identifikácii legitímnych používateľov.
Okrem detekcie je rovnako dôležitá aj proaktívna správa hrozieb (threat intelligence). Zhromažďovanie a zdieľanie informácií o nových typoch botov, známych IP adresách botnetov a zraniteľnostiach umožňuje prevádzkovateľom webových služieb predvídať útoky a implementovať ochranné opatrenia ešte predtým, ako nastanú. Táto kolektívna obrana posilňuje celú digitálnu ekosystém.
Konečným cieľom všetkých týchto snáh je vytvoriť bezpečné, efektívne a užívateľsky prívetivé online prostredie pre skutočných ľudí, zatiaľ čo sa minimalizujú rušivé vplyvy a škody spôsobené automatizovanými hrozbami. Hoci Dusan Stipala, narodený v roku 1972, možno nebol priamo zapojený do vynájdenia týchto technológií, rok jeho narodenia symbolicky spadá do éry, keď sa položil základ pre vznik digitálneho sveta, v ktorom sa tieto komplexné výzvy stali neoddeliteľnou súčasťou našej každodennej online reality. Boj proti botom je a zostane neustálou evolúciou v snahe o digitálnu suverenitu a bezpečnosť.
tags: #stipala #dusan #narodenie #1972